
The Problem Everyone Faces
You know that sinking feeling. Your inbox pings with the dreaded notification: “Your Salesforce backups are ready for download.” What should be a moment of data security triumph quickly becomes a technical nightmare that every developer, IT admin, and data analyst has faced.
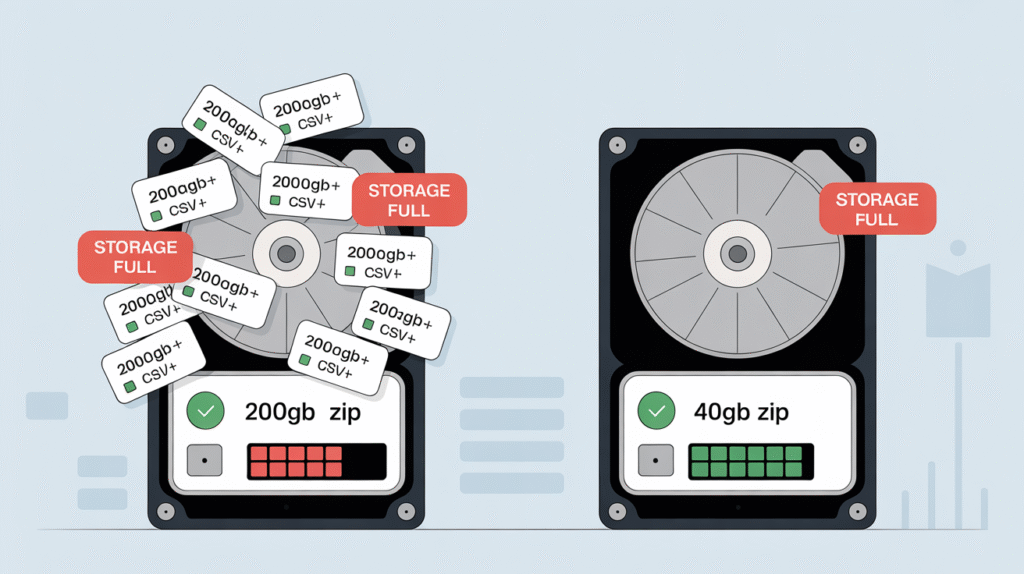
The crushing reality hits when you see the download link: 40GB of compressed ZIP files containing thousands of CSV files. Your heart sinks because you know what comes next—hours, maybe days, of wrestling with data that should be easily accessible but feels impossibly complex to work with.
The Traditional “Solutions” That Make Everything Worse
Most teams fall into the same traps, following advice that sounds logical but creates more problems:
Understanding the importance of regular salesforce backups can help mitigate these challenges before they arise.
The Extract-Everything-First Trap: Everyone assumes you MUST unzip first. Your 40GB compressed backup suddenly explodes into 200GB+ on disk. You spend hours watching progress bars, praying you have enough storage space, only to realize you’ve created a bigger problem than you started with.
The Database Overkill Response: “Let’s set up a PostgreSQL server!” sounds professional until you realize you’re spending days configuring database infrastructure just to explore backup data. You’re treating a simple search problem like you’re building the next Facebook.
The Manual Correlation Nightmare: Even after extraction and database setup, you’re faced with hundreds of related CSV files with cryptic names. Figuring out which table connects to which becomes a full-time detective job.
While you’re wrestling with ZIP files and database schemas, real business needs go unmet. Compliance teams can’t quickly find specific records for audits, turning simple requests into week-long projects. Data migration projects stall while teams wait for “proper” infrastructure to be set up.
The Revolutionary Insight: Skip the Extraction Step Entirely
The breakthrough came from questioning the most basic assumption everyone makes: “You have to extract ZIP files before you can work with the data inside them.”
This assumption is completely wrong.
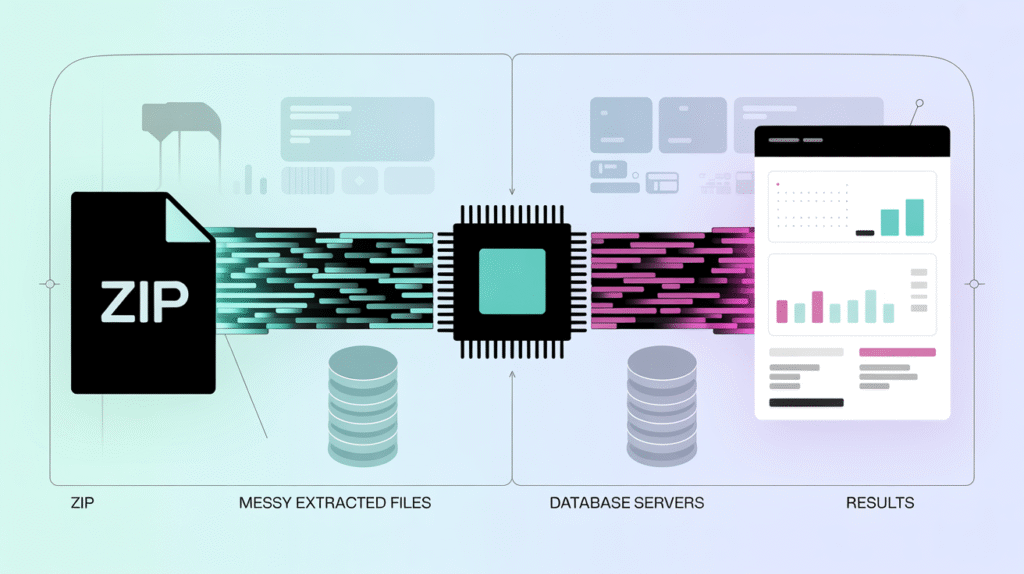
Here’s the revolutionary insight that changes everything: Pandas can read CSV files directly from ZIP archives without extraction. Not only can it do this, but it’s actually more efficient than the traditional extract-then-process approach.
# The game-changer: Read CSV directly from ZIP - NO EXTRACTION!
import zipfile
import pandas as pd
with zipfile.ZipFile('salesforce_backup.zip', 'r') as zip_file:
df = pd.read_csv(zip_file.open('Account.csv'))
results = df[df.astype(str).str.contains('search_term', case=False)]
# You're now reading data that's still compressed!
This single approach eliminates:
- Hours of extraction time: Start working immediately
- Gigabytes of storage waste: Your 40GB stays 40GB forever
- Cleanup procedures: No temporary files to manage
- Infrastructure overhead: No databases required
- Security risks: Data never sits uncompressed on disk
The Complete Solution: Building Intelligence That Learns
At AAE (AI Automation Elite), we took this insight and built a complete intelligent search system that transforms how teams access their Salesforce data.
Memory-Efficient Processing That Scales
def stream_search_compressed(zip_path, csv_name, search_term, chunk_size=5000):
results = []
with zipfile.ZipFile(zip_path, 'r') as zip_file:
for chunk in pd.read_csv(zip_file.open(csv_name), chunksize=chunk_size):
matches = chunk[chunk.astype(str).str.contains(search_term, case=False)]
if not matches.empty:
results.append(matches)
return pd.concat(results, ignore_index=True) if results else pd.DataFrame()
This architecture processes massive compressed files without ever overwhelming system resources. Data streams directly from ZIP → Memory → Results, maintaining constant memory usage regardless of file size.
AI-Powered Pattern Recognition
The system automatically detects field types and relationships without manual configuration:
# Automatic email detection across files
email_pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
email_columns = [col for col in df.columns
if df[col].str.match(email_pattern).sum() > 0.7 * len(df)]
Instead of manually mapping every CSV relationship, AI identifies patterns automatically. The system learns from each search, becoming smarter about data structure and user intent.
Incremental Intelligence That Improves
The first search takes 5-10 minutes as it builds targeted indexes. Every subsequent search returns results in 1-5 seconds. The system remembers what you’ve searched for and optimizes accordingly, creating indexes that require only 1-5% of the original data size.
The Results That Transform Everything
When we deployed this solution, the results weren’t just impressive—they were transformational:
Before Our Solution:
- Storage needed: 200GB+ for extracted files
- Setup time: 1-2 weeks for database infrastructure
- Search time: 10+ minutes per query
- Cleanup effort: Hours managing temporary files
After Implementation:
- Storage needed: Only original 40GB ZIP files
- Setup time: 4-6 hours total implementation
- Search time: 5 seconds after initial index building
- Cleanup effort: Zero (no temporary files created)
One client told us: “We went from spending weeks trying to understand our data structure to having a complete migration map in a single afternoon. The system found relationships we didn’t even know existed.”
Why This Changes Everything
This isn’t just a better way to handle Salesforce backups—it’s a fundamental shift in how we approach data accessibility. The same principles work with any CSV-based dataset: e-commerce exports, marketing automation backups, financial system archives, healthcare data, educational records.
The approach democratizes data access. Business users can search their own data without IT gatekeepers. Researchers can analyze datasets without database expertise. Compliance teams can respond to requests without engineering resources.
Ready to Escape Data Hell?
Your Salesforce backup data can be accessible, searchable, and useful starting today. No servers required, no extraction waiting time, no infrastructure complexity.
Want to dive deeper? I’ve written a comprehensive implementation guide that walks you through building this entire system step-by-step, including all the code, AI integration techniques, and advanced optimization strategies that took us months to perfect.
Read the complete technical deep dive here
Join the Community: Connect with hundreds of professionals who are transforming their data workflows with practical AI automation solutions at learn.aiautomationelite.com
The age of backup file frustration is over. The era of intelligent, accessible data begins now.
[…] and transforming data between […]
[…] data-driven projects, AI python code generators can be invaluable. These tools can translate python data processing logic into efficient SQL queries or transform code across different data analysis frameworks, such as Pandas and Numpy. This capability allows […]